Jenny Brady’s work is preoccupied with communication. Her films inquire into what delimits, delays or denies a being’s capacity to send (to speak, sign, signal) and to receive (to read, interpret, understand). In Wow and Flutter (2013), that communicating being is represented by a bird. A cockatoo occupies the lectern of an empty auditorium still haunted by residual “non-voices”,[1] the coughs and interstitial oral effluvia of assemblies past. In Bone (2015), these concerns are channelled round the figure of a Labrador retriever: a dog made the unwilling, chimeric object of predatory banter manifesting as open caption text. In Going to the Mountain/Spikes, a sequence of babbling, glitching infants glitch out transitions between orality and verbality. This essay, however, will concentrate exclusively on Receiver (2019). Not because these earlier films are not fascinating; (they really are, and warrant essays of their own). Rather, the aperture of my attention is narrowed because this piece demands scrutiny today. I want to read Receiver in the context of conversations right now live (if video-virtual) about captioning, inclusivity and the in/accessibility of audiovisual media.
Owing in part to the artist’s long, fruitful collaboration with Andrew Fogarty, Brady’s films are lushly soundscaped. And though their sound design, too, deserves proper attention, this essay is much less concerned with the acoustic apperception of Receiver than it might be in different hands, or at another moment. That is not to say that the analysis that follows is not very much about sound and/or its translation. In an attempt to sustain the attention Brady directs to the production, onscreen operation and reception of captioning, I will focus especially heavily on the film’s caption track. To avoid reproducing the sensory presumptions calcified in allusions to “audiences” (who must hear) or “viewers” (who must see) the work, I refer to these addresees or readers as receivers throughout. To convey the rhythmic segmentation of caption text, line breaks are preserved with punctuation, as in poetry.
In 2020, Jenny Brady devised an exhibition with LUX that brought a polyphony of (sonorous and non-sonorous) voices to bear on the concerns animating Receiver. This presentation of the film was immediately followed by a series of D/deaf Artists’ Film Commissions, as part of a programme exploring access, that is now fully (wonderfully) underway. Brady’s exhibition for LUX decentred the artist-as-author, modelling a centrifugal impetus that also structures Receiver. In keeping with the ethic embodied in Brady’s practice, and with a nod to the reading list she provided for the show, this essay will dwell on detail, whilst (and through) being intentfully oriented toward the invocation of interlocutors, and the citing of relevant texts.
Running to just under 15 minutes, Receiver is composed of 5 distinct parts or scenes, of which the third and fifth scenes are visually though not aurally of a piece. These scenes interrelate formally in a composition that is, at each layer of its multimodal construction (still and moving image, sound, text), profoundly rhythmic. Through its precise orchestration of how these channels are made to cede to, crosscut and override each other, Receiver forecloses the possibility of smooth reception, and denies the availability of a totalizing apprehension. A complex of knotty concerns extends between its parts, becoming only thicker and more richly co-imbricated as the film plays out. The object of this essay is neither to smoothen nor to flatten the complexity of what is instantiated in the interrelation between these movements. Receiver is a film that critically, concertedly takes “access as a primary material”, and, in multiple ways, as its subject.[2] In doing so, its every part conscripts or choreographs another, unfamiliar, un-whole form of engagement from those who seek to receive it. In what follows, I will read the film as a heuristic through which to think about histories of broadcast justice, and the imperatives of postdigital communication. Receiver is a device that makes tangible the grain of the gears of one’s own sensory and cognitive perception, at the same time that it situates those perceptual mechanisms as mediated phenomena within a field of social, political and cultural forces.
Receiver, Jenny Brady, 2019
1: [ring, ring]
The first scene of Receiver unrolls as an open caption track with synchronous vocals. White text scrolls against a black background otherwise broken only by still images that flash momentarily into view—black and white photographs that disappear so quickly that some are gone before ever they’re glimpsed. A recurrent sonic signal trains hearing viewers into paying close visual attention to the apparitions that intermit behind the text. Corresponding with the brief advent of each fugitive photo, the clack of a slide slotting into place on a projector carousel teases the tardy; it taunts the receiver who happens to blink at the wrong moment with awareness that something has been irretrievably missed. When this crossing of sensory inputs occurs, image is made sound: mirrored inversion of the transubstantiation of audible speech into text via the captions.
The photos shown, if not all entirely seen, are archival images: mass media metonyms for major events in the histories of D/deaf education, D/deaf history and Deaf Pride. Many depict jubilant groups of banner-carrying demonstrators in the Deaf President Now protest which took place at Gallaudet University from March 6-13 1988. DPN quickened the momentum to bring about a change already 124 years overdue. Three qualified candidates had been considered for the role of President of the institution, two of whom were Deaf and used sign language. As Kristen C Harmon neatly recounts: “When Elizabeth Zinser, the hearing, nonsigning candidate, was named the new president, angry and disappointed students and alumni staged a protest and shut down the campus”.[3] Revolt produced reform, and Dr I. King Jordan was named the first Deaf President of the university on March 13th 1988. A number of photos show Alexander Graham Bell engaged in demonstrations of a particular pedagogy: teaching methods he promulgated to eliminate the use and teaching of sign language “and to replace it with the exclusive use of lip-reading and speech”.[4] This ideology, known as “oralism”, drastically shaped the education of D/deaf children in the U.S. and elsewhere from c.1880-1957. Other photos are remnants of a glossy, celebrity-endorsed propaganda drive: staged scenes of instruction at the oralist Clark School.[5] Ubiquitous as any hegemonic dictator, Graham Bell also features here in effigy (as icon): as the subject of portraits propped in Clark School classrooms, and that of the biography chalked onto Clark School blackboards. Interspersed among the DPN and AGB pictures, a photo of Prince with fans, and a still from Seinfeld look incongruous only until the exuberant ruffles of a shirt place the singer at his 1984 concert at Gallaudet, and the woman sharing a table with Jerry & co is identified as Deaf actor Marlee Matlin. Only Prince does not return later in the film.
Infamous as the forbiddingly bearded poster-boy for the oralist attempt “to unmake [Deaf] community and culture”, Graham Bell is also famous for the telephone.[6] And it is a telephone conversation (or, arguably, two crosscutting, contemporaneous conversations) that is relayed by the open captions in Receiver’s second scene. When an unlikely “[CROSSED LINE]” causes an “[UNKNOWN CALLER]” to break in across the exchange between an AT & T telephone company agent and a “[FEMALE CALLER]” called Shauna, the interjecting voice opens on a courteous note: “Hi Ma’am/ I’m sorry to call so early, um/ May I please speak to –/ Melissa?”. But within less than two minutes, the same uninvited though unwitting interloper on the call is addressing an all-caps tirade to the agent-turned-switchboardist: “NO, BITCH/ WATCH YOUR FUCKIN MOUTH/ ALRIGHT, BITCH—/ WATCH YOUR FUCKIN MOUTH, ALRIGHT/ DON’T START FUCKIN ROUND, HO”. In the wake of this outburst, an answering “[DISCONNECT TONE]” is carried by captions and audio track alike. What transpires between these three accidental interlocutors is a comedy of confusions. In apprehending the Unknown Caller’s fury at being momentarily discommoded—unable to make their message carry to its intended destination—Receiver’s receiver is cued to evaluate their own expectations of access to felicitous, untrammelled connection. As it proceeds, the film will prompt them to weigh these against those of differently sensing, differently communicating bodies.
Brady’s captions on this scene stretch the conventions of the form, as though testing their capacity to communicate more than words alone. An exclamation that cracks with outraged incredulity is rendered typographically: “exCUSE ME?” A sardonic hyper-articulation of slow-dawning realisation is made to come up all caps: “OHHHH, WOW”. Assertion of ownership is carried by an amplification of the possessive pronoun: “Well, can you/ hang up the phone, Ma’am because you’re on MY line”. Repetition of a single phoneme works as filibustering refusal to cede space: “N-n-n-n-n/ No./ You guys are on my line”. Brady’s pacing of the cadence of these captions corresponds exactly to that of the audible speech that plays out in synch as sound—pausing the flow of text mid-clause in evocation of vocal hesitation, making numbers appear onscreen in the same 3/4-digit mnemonic bundles as they do when spoken, in what Sean Zdenek—taxonomist of caption forms— would call “chunking by phrase”.[7] While trespasses in turntaking and “latching” (when speakers talk almost simultaneously, sometimes overlapping) present problems for captions that are confined to one or two lines centred at the bottom of the screen,[8] the crossed line scenario poses a particular predicament—requiring that the captioner chooses which of two overlapping voices to represent textually in a given frame. The hearing reader will notice that it is the filibustering “N-n-n-n-n” rather than the AT & T Agent’s contemporaneous, uncaptioned suggestion that “you try making your call again” that is determined to be the more important line to relay onscreen. Overlaps can make captions a lossy medium.
Other divergences between the streams accentuate the gap between the verbocentricity of subtitling (which captures speech alone) and the fullness of captions, which, whether open or closed, render into text all relevant or significant sound. That, at least, is the principle, but the proliferation of automated “captioning” that uses speech recognition technology to relay an often sketchy semblance of the words spoken, ignoring (and so eliding) all other sound. As Elizabeth Ellcessor concludes, these bare, too-often garbled automated transcription of speech “[dilute] the quality of this method of access and [devalue] the nuanced cultural work involved in producing these translations”.[9] Automation delivers “essentially a subtitling service masquerading as a captioning service”—not always reaching even the shamelessly low, “better than nothing” standard Google set itself in 2009.[10] In March 2021, the company announced Live Caption for Chrome, framing the need for this new auto-caption tool as the solution to a perfectly (aw shucks) passively-constructed problem: “Unfortunately, captions aren’t always available for every piece of content”.[11] While the relative merits of this new deferral of responsibility to AI speech-to-text technology remain to be debated, Google’s grammatical avoidance of verb subjects—the agents who do or do not provide captions on online “content”—is not encouraging.
Ascriptions of gender on the basis of vocal timbre are, of course, always fraught, subjective, fanciful, arrived at via the hidebound thinking of what Nina Sun Eidsheim calls the “figure of sound”. This tautological paradigm “reduces sound’s being and its attendant listening practices to sound’s relative relation to a range of a priori ideas of sound”.[12] In Receiver’s caption track, it is only the “[FEMALE CALLER]” who is thus externally assigned a(n assumed) gender identity, leaving the agent and unknown caller blithely unmarked. While speaker identifiers tell the caption reader who is speaking, manner of speech identifiers tell caption readers about how they speak (e.g. pitch, volume, intonation, timbre, emotion).[13] In the absence of any such information here, the reader must make do with what is encoded typographically. Working within the considerable spatiotemporal constraints of the captionstream that usually allows no more than 2 stacked lines/layers of text, captioners make decisions about what their readers need to know. Enhanced consciousness of those decisions as motivated, inflected choices can only improve the odds of arriving at equivalence among receivers, at equality of access.
The captionable content of a phone call is not limited to the wordcount of what constitutes intelligible speech. Receiver’s captions relay the fact that “[FEMALE CALLER] … [LAUGHS]”. But they nowhere acknowledge the considerable sonic distortion on the line. In transposing audio from phone recorder to the film (via the intermediary of YouTube), Brady makes this low sound quality newly appreciable. Thus transplanted and recontextualised, it comes to signify—priming the hearing viewer to attend to the conduit as well as the content of their conversation. That content is, of course, all about the mal-functioning of the telephonic medium. The presence of nerve-fraying interference on the line explains and presumably contributes to the speakers’ irritation. It also imparts to a listening viewer information about their embodied use (proximity of mouth to mouthpiece, motion, etc) of their respective phones. As Lori Emerson and others have noted, what characterizes the interfaces of our 21st-century “ubicomp” environments is their aspirations toward frictionless, seamless invisibility. The “dream the computing industry rides on” is the promise of a “more natural, more direct, inherently better way to interact” with and through.[14] Trying to be intangible, invisible, inaudible, these interfaces contrive not to register. Not so the telephone in the opening of Receiver. This crackling conduit does not only inflect what passes between them. Instead, via the chance crossing of lines, the medium of their unintended three-way conversation brings it about in the first place.
Receiver, Jenny Brady, 20192: [questions on a postcard, to this addressee]
Later in the film, misbehaving technologies assert themselves still more intrusively. In the penultimate scene, the fourth of five, raw footage of a screening of Orson Welles’ The Trial at University of California San Diego in 1981 turns up with Brady having excised all aural and visual traces of Welles himself. From what remains, she constructs a compellingly abstracted composition in intermittent text, sound and image. Out of these deliberately disaggregated streams of sensory input, the receiver must compose, in turn, an interpretation. The campus shoot was dogged by technical breakdowns and the resulting footage patchy and partial, watermarked throughout by the evidence of what didn’t work. But even with the bearded guest of honour cut out, the video Brady rescues from this abandoned project still carries into the film a notably warm, convivial atmosphere: an ambience amply conveyed by captions which record “[RIPPLE OF APPLAUSE]”, “[AUDIENCE LAUGHTER]”). Whereas the original event was all about the auteur, Brady constructs from it something entirely other. Enacting an instruction imparted in a line from Wow and Flutter, Receiver makes the presumed “hearers” (in the auditorium) the new speakers, in a scene that transforms student fans from congregation to co-celebrants in an experience of shared enthusiasm. She makes the floor the stage.
Under Brady’s reversal of figure and ground in the footage, gappy audio and image tracks are recast as semi-abstract washes into which irrupt captioned text, sounds and images. The centred scroll of the captiontrack meticulously records occasional ambient sounds— “[METAL ON METAL]”, “[STEEL ON CONCRETE]”, “[THUD, FOREGROUND]”. Heard elsewhere, and without either accompanying image or description, the sources of these sounds would be identified by only the most forensic of listeners. As Zdenek notes, the meaning of many such sounds “only becomes secured in context”.[15] Beyond merely recording the occurrence of sound events, the captions give the reader extra information about their nature, location, the materials involved. What might register for a non-reading hearing person only as nonspecific sonic intrusion/breakdown—noise suspending transmission—is elucidated by the captions as extra information.
Because Welles originally intended the footage to feature in a film essay, a sound recordist was tasked with the unenviable job of locating and miking questions from the floor. Their progress round the room and location relative to the other mic and speakers register as feedback squeals, whistles, electroacoustic wails sent up by machines interacting. It is from these beeps, screeches and unplaceable tones that Brady and Fogarty build up the soundscape that backs this scene. Left to chase down the source of each prospective question from any place within the auditorium, the sound recordist’s frustration registers in the faux jocular, rueful laments, intended to prod the crowd into more ordered, amplification-aware behaviour: “I don’t see/ where this person is/ He’s hiding”.
Comparable communications-tech breakdowns haunt all such spectacles of publicly conducted conversation. Receiver’s amplification and overlayering of the record of these failures (inaudible questions, machine-sound mayhem, repeated requests for repetition) remind us of an important, under-observed fact. All of what is considered the (normatively conceived) “basic” equipment required to run a public event/screening etc is in some sense assistive technology. That includes the microphone that makes Welles’ (here unheard) responses audible to his live congregation, the roving microphone that makes his inquisitors (ultimately) audible to him across the space, the seating that supports the students’ backs, making them able and willing to stay static for the long duration of the event, and the lighting that makes their facial expressions mutually intelligible.[16]
Every (artist) Q&A is necessarily an exercise in partial communication and comprehension, even before questions of technological capacities or sensory dispositions are explicitly brought to bear. In another figure/ground inversion, Brady salvages and centres the ubiquitous background of the public art conversation: attempts to improve communication between parties, prompts from the sound recordist to “speak up please”, phatic hesitations within sentences while speakers mentally formulate questions they have already started to speak “as you express it—/ eh, ah—/ seems to say that”. Running beneath the sometimes contorted surface of these repeated, inaudible, bumbled and fluffed questions is the abiding impasse that troubles any translation of cinematic language into spoken English: the processing of filmic thickness into sentences composed live, from the lectern. A further translation is enacted onscreen in the rendering of those utterances into text.
Publicly staged conversations invite participants to engage in a kind of devotional listening; they also promise (if the mic can locate the would-be speaker) an opportunity (let’s take some questions from the floor) to perform extant knowledge (i.e. the stuff slid under the door as “more of a comment than a question”). To take part is to play a role in an improvised ensemble. In this scene, receivers-turned-speakers are identified by reference to their manner of speech. These captions order participants according to an idiosyncratic though evocative system of identifying voice types and behaviours: “[TAUT VOICE] …. [SWOLLEN VOICE] … [CASUAL VOICE]”. When one “[DISTANT VOICE]” is redescribed soon after as “[DISTANT VOICE, AMPLIFIED]”, the caption-reader reconstructs a victory on the part of the recordist. Just as the ambient sounds are recorded as meetings between substances, and not as sound events as such, unlike many other potential voice descriptors, those Brady uses here do not rely on the caption-reader having hearing memory. (Conversely, a reference to a shrill, deep, or nasal voice could be useful to only some D/deaf readers—registering as obstruction and not information for others).
Sweeping blurrily round the San Diego auditorium in search of the unscripted speakers from the floor, the camera occasionally comes to rest on the listening faces of individual audients, capturing expressions lit by ardent fandom and the pleasure of being part of the crowd that laughs together. When necessary, such as when a single voice fails to carry –“[SOUND RECORDIST] Can you repeat that?/ [SECOND VOICE] Can you speak up please?”—the assembled crowd respeaks the lost-in-transit question together as a chorus of “[MANY VOICES]”. The distinction between signal and noise is not a simple one when so much of what is spoken articulates not questions as such but social gestures encoded in language, performances whether of deference (“I was wondering […] Excuse me—”), or of mastery (“Uh, one of the things that I find/ most interesting about the film is…”). As Brady’s film so eloquently articulates, what is billed as an “audience with” or “in conversation” with a designated speaker is an event instantiated between—rather than for—multiple communicating, collocated bodies. Leaving aside the Welles fan who might regret the elision of the director’s responses, watching Receiver in this plague year, it’s the feel (sonically, visually and textually relayed) of the crowd responding together, as a temporally constituted multi-body many-voiced conglomerate that tantalises here.
Receiver, Jenny Brady, 2019
3: [intermission]
The equivocal affordances of technologies that variously facilitate or foreclose access are approached from yet another angle in Receiver’s remediation of a clip of Deaf YouTuber and anti-craption campaigner, Nikki Poynter. In the film’s caption and audio-tracks, Poynter talks about how she hears herself—and how differently she experiences the sound of her own voice “when I speak out loud/ like right now/ and when I listen back to myself/ when I’m editing a video”. While the voice picked up by her residual hearing is, she says, “a much more high pitched voice”, the audio output on her computer, when received via earphones, gives back a voice that to her “sounds very deep,/ it sounds more of a Deaf accent”. Poynter’s exclamation at how “the comments [on her YouTube channel] go/ ‘why does she sound like a man’?”, suggests an intersectional extension to Eidsheim’s figure of sound. Transposed from YouTube into the context of artists’ moving image, Poynter’s wry monologue also inevitably recalls Nancy Holt’s realtime narration of her experience of her own machine-mediated speech in Boomerang.
For each scene of Receiver, Brady furnishes another style of captioning: showcasing options as to placement, background, size, thickness, pace, segmentation and line length. The stylistic inconsistency that results is anything but accidental—functioning instead to further heighten the receiver’s awareness of precisely how they receive her speech made legible. The captions that present Poynter’s (simultaneously sonorous) speech pop on and off in sentence case, in a serif font, in synch with the cadence of her vocal delivery and in single-layer lines that are allowed to stretch out long across the bottom of the screen. These speaker-specific features render onscreen the heightened attention she is inviting the YouTube subscribers to bring to her vocal pitch, tone and accent (“THAT sounded Southern”) in this episode. The appearance of Poynter’s captions nods too to the origin of a recent foment of (not always FCC-compatible) innovation, producing “accelerating variety of styles of open captions […] in online videos”.[17] Here and elsewhere, Receiver primes its receivers, and perhaps particularly the hearing quotient thereof, to notice captioning—and, more urgently, its absence and automated insufficiencies—in their everyday media ecologies. Receiver propagates heightened attentiveness to the “transformative, even radically interpretative power of captioning to shape the meaning and experience” of artists’ moving image.[18] By passing between film festival, gallery installation and (as at LUX in autumn 2020) web-based exhibition contexts, Brady’s film intervenes in multiple moving image environments: all of which are engaged in their own reckonings with a (long campaigned-for) realization: ie that the translation of sound into text onscreen matters.
While Poynter’s audio and caption tracks play (as well as in the film’s closing scene), refracted reinterpretations of the Clark School scenes return. Tenderly shot new footage from an acoustic foam-lined sound studio shows two children (Eva and Ala) being aided by their mothers in adopting reminiscent poses—blowing out the candle we have already seen extinguished, holding a hand under a chin or patting it over an open mouth, in haptic engagement with sound as vibration. Meanwhile, captions duly record the soundscapes accompanying these images: [BIRD CALL], Beethoven’s “[DUO FOR CLARINET AND BASSOON IN C MAJOR]” and the BBC Radiophonic Workshop’s Tamariu (from the 1973 Fourth Dimension release). Where the opening scene’s archival photos of D/deaf pupils practicing similar techniques presented stiffly smiling children, Brady’s camera observes them in unscripted, expressive motion, signing in ISL. At the end, Eva removes the headphones with the barely contained relief of a child skipping from desk and duty, job done.
Receiver, Jenny Brady, 2019
4: [recaptioned]
On March 9th 1988, ABC broadcast a special edition of Nightline that brought news of Deaf President Now to the mass TV-viewing public. From the studio in Washington, Ted Koppel interviewed three people, each of whom appeared, in zoom-familiar form, in separate, purple-highlit boxes onscreen. Greg Hlibok, President of the Gallaudet Student Body, and actor and honorary Gallaudet graduate Marlee Matlin (she of the Seinfeld episode that flashed by earlier) were joined by newly elected University President Elizabeth Ann Zinser, the overt unfitness of whom is accidentally underlined when Koppel refers to her as “a hearing woman who is just now learning sign language”. Of course, as Hlibok explains later in the programme, this means that, notwithstanding whatever claims Zinser will make in defence of the appointment, “SHE DOESN’T HAVE ACCESS TO THE COMMUNITY, UM, AND THERE’S NO DIALOGUE”. In Receiver, Brady reprocesses, reshoots and recaptions material from this historic broadcast.
Introducing the broadcast, Koppel advised Nightline viewers that in a special one-time only acknowledgement of the needs of D/deaf and Hard of Hearing public, the ordinarily closed caption track would be made open (i.e. would be automatically visible via all television receivers). Koppel’s semi-apologetic warning that hearing people tuning in “may find it momentarily distracting” to see text on their screens encapsulates debates then afoot (and still lingering in some quarters today) about the “rights” (so-framed) of hearing consumers not to see open captions.[19] For a time during the American captioning wars, open provision—“artistically more adaptable, economically more palatable, and arguably more democratic”[20] than the closed caption alternative— looked like a viable option for American TV. For one especially brief period in 1981, prior to a subsequent overruling, it was even ruled that only captions that were open (and so required no additional outlay) met the definition of “equal access”.[21] But television networks hesitated. Rather than risk momentarily discomfiting the hearing public so dear to advertisers, television networks opted to maintain the en-closure of captions as an assistive add-on, made legible via a separate decoder appliance.
The road back is a long one. It was not until 1993 that the Television Decoder Circuitry Act mandated that new televisions with screens of at least 13 inches manufactured in or imported into the U.S. were required to be pre-equipped with decoder chips and not until 1996 that US TV broadcast stations and providers undertook to provide closed captions on nearly all English language programmes by 2006. Notwithstanding the crucial victory won in the Netflix/National Association for the Deaf case of 2012, the legal status of captioning for online videos remains in what Elizabeth Ellcessor rightly terms “a kind of purgatory”.[22] How this purgatorial state might evolve (or not) towards eventual access heaven or hell in the wake of a new pandemic-prompted awareness of these issues remains to be seen and/or heard.
In his Nightline intro, a magniloquent Koppel suggests that the prevailing inaccessibility of the network’s closed caption provision was news to the TV studio, announcing: “It’s been brought to our attention that a great many deaf or [hard of hearing] people don’t have access to a closed caption set so tonight, you can all read along as you listen and watch”.[23] Then, as now, access was prone to be framed as an issue of economic pragmatism. Decisions about captioning continue to be made on the basis either of business cases (the SEO-boosting argument for captioning online videos) or convergence curb-cuts (the amalgamation of potential hearing beneficiaries, e.g. language-learners, at-work watchers).[24] The repercussions of this attitude manifest in the Nightline episode through a sponsorship statement by “KRAFT, INC/ MARKETER OF KRAFT FOOD AND/ DURACELL BATTERY PRODUCTS” that appears in place of the caption stream. By taking over the line 21 “hiding spot”—the vertical blanking interval that contains no picture information—while Koppel continues to speak, this statement retards the caption track. As a result, the delay inherent in live captioned broadcasts (today, typically of c.5-7 seconds)[25] is significantly extended. The voice/text mismatches that result speak of the TV company’s privileging of an oblique advertising opportunity over the legibility of the caption track—notwithstanding (or not understanding) the likelihood of confusion arising when the words displayed outlast the presence of their speaker onscreen.
The original captiontrack is also rife with typos. Similar sorts of transcription errors—“if ever” rendered as “IF OF” “buttressed” reimagined, creatively, as “BUT TRESSED”—are everywhere in the era of automatic “captions” (more on these scare quotes anon). At one point in the Nightline transmission, a dilatory digression on the part of one panellist appears to have caused the beleaguered captioner to weary, with the result that the vocalized word “expressed” appears as a garbled “EXPREGSO”. For the D/deaf caption reader, the massing of these mistakes is more than an inconvenience. Errors pull attention from message to medium, leave gaps, frustrate understanding and undo access. In Receiver, Brady’s new, sentence-case track corrects the errors present in the Nightline original. The artist scrubs the caption copy of its typos in acknowledgement of the importance of the conversation it records: her recaptioning a retroactive restoration of respect.
Captioning, as Greg Downey observes “suffers from a visibility paradox”.[26] Too often, captions are noticed only when an error snags the saccading eye. Shannon Finnegan and Louise Hickman’s film, Captioning on Captioning undoes the invisibility of CART labour. This short, collaborative work was commissioned by LUX as part of the D/deaf Artists Commissions in 2020. Via tripartite conversation between the artists and the CART-writing J”ennifer”, Captioning on Captioning opens videoconferencing windows into the “stenographer slash real time writer slash captioner”’s steno-brief dictionary (a vast, individually-collated compendium that could contain “well above a hundred thousand entries”[27]. Jennifer explains how she programs her personal computer with client-specific dictionaries while simultaneously demonstrating her highly expert deployment of those same dictionaries in the text that is appearing onscreen. The three-way conversation constitutes a live-videoed exemplification of how “The moment of access is ultimately individual, but relational, existing in connections between hardware, software, bodies, minds, and cultural and material contexts”.[28] In the film, Hickman talks of how “Sometimes when people are talking and they are going on and on, it’s kind of like a stream of consciousness…the captioner…you can see the captions sort of breaking down”. This breakdown is inscribed in the consonantal pileup of “EXPREGSO”—producing in the caption-reader sudden consciousness of the embodied, interpreting, decision-making worker behind the almost instantaneously-appearing text.
In her authoritative (and, in its effects, activistic) art criticism, Emily Watlington valorizes captioning as creative practice, and argues for the retrospective captioning of historic works of video art. Her argument persuades by excavating the “radical accessibility” baked into these videos that, though latterly misrepresented as immutable “mutual objects”, were largely intended for transmission as art accessed via domestic televisions (where it would now be captioned as a matter of course).[29] In a talk on this topic for LUX, as well as across her prolific writing, editing and curating, Watlington has focused attention on the brilliance of caption-driven, captioning-themed works by artists such as Carolyn Lazard, Liza Sylvestre, Christine Sun Kim, Amalle Dublon, Joseph Grigeley, and Constantina Zavitsanos. Watlington presses an art world that “often perpetuates exclusion, continually assuming only sighted and hearing audiences”,[30] to reconsider its resistance to captioning, to evaluate “this aesthetic distaste, and whom it privileges”.[31]
Receiver contributes in a different though related way to the collective project of pointing up how communications infrastructures and art environments alike disclose the “normate templates”[32] and “preferred user positions” underlying them—the ways in which they are “set up for particular audiences and tasks, often in such a way as to privilege normative articulations of bodies, technologies and cultures”.[33] Brady’s film tips the sighted, hearing receiver out of the preferred user position (the comfy seat they have learned to expect), setting them on the “back foot” instead. Contending with partial views, interrupted audio, and confusingly crossed sensory input-lines, trying to interpret the significance of images that vanish too fast, and denied access to the audio of the famous director’s answers, the film’s receiver has to work to get at information pushed out of their immediate reach. In apprehending the materially and conceptually reframed DPN interview scene, these receivers have to puzzle out what is going on between panellists shorn of the onscreen name-identifiers, their contributions no longer prefaced with the presenters’ intros, their talking heads brutally cropped. The experience may be unfamiliar and the effect, hectic.
Retrospectively breaking every rule of interview videography, Brady fills the screen with speakers’ elbows, shoulders, shirt-fronts, barely ever bringing full views of faces into unobstructed view. Slicing across exchanges between opposing sides, the artist sutures, crops and collages audio and image tracks to instate new causal links, as well as to sunder those discernible in the original broadcast. When Koppel recommends that the Gallaudet Students ought to be prepared to entertain yet another hearing President, asking in odious faux-reasonableness, “<<IS THERE ANY ROOM FOR/ COMPROMISE IN YOUR/ POSITION AT ALL?”, Brady cuts across the zoomed-in re-recording to a closeup on Hlibok’s face. With newly-magnified composure, the student leader receives his ASL-translator’s signed interpretation of the presenter’s question. Then emphatically, efficiently shakes his head, before signing again the rousing rejoinder “WE REGRET THAT, UH/ WE DO NOT WANT TO/ COMPROMISE AT ALL/ BECAUSE WE HAVE BEEN/ MAKING MANY CONCESSION/ FOR MANY, MANY YEARS”. Vestiges of the original captions scroll by behind the new track, half in, half out of the frame, their over-magnified words abstracted out of legibility, while Brady’s captions scroll onto the screen as an upper-case white-on-black scroll. Relegated to a new role as kinetic, decorative feature, their all-caps consistency works as an atavistic remainder (a typographical tail maybe) from an earlier period when the quality of caption-printing technology was such that an unrelenting upper case (now reserved to convey shouting) was necessary for legibility.[34]
In Receiver it is the hearing viewer—or at least the hearing viewer without prior knowledge of DPN as a momentous event for Deaf Pride—who is placed at an informational disadvantage, cut out of following the conversation. Awareness of the events at Gallaudet in March 1988 is what makes this scene of Receiver readily intelligible. Conversely (and complementarily), the lack of that core cultural knowledge in the receiver is what makes it possible for the film to activate a state of frustrated, tantalised bafflement. In cutting the ordinarily privileged receiver out of the conversation, the film makes access tangible as contingent, constructed.
Receiver lifts to new visibility in a new century the egregious paternalism exhibited, and bounced back and forth between the programme’s hearing participants. The film shows Zinser acknowledging the existence of “A VERY/ STRONG SENTIMENT” contesting her appointment, but pronouncing herself nonetheless, and in spite of having only just arrived on campus from her previous North Carolina appointment, “NOT CONVINCED”. Manifestly insensible to her new institutional context, she suggests that Gallaudet “DESERVES TO HAVE […] THE CONTINUING/ STRENGTH INTO THE FUTURE/ IN ITS MISSION AS AN EDUCATIONAL INSTITUTION AND A SIGNIFICANT RESEARCH INSTITUTION”—insinuating, as her co-panellists readily observe, that “A DEAF PERSON CAN’T/ CONTINUE THAT FOR/ THE FUTURE”. At this, a particularly wince-inducing high tone seems to signal that even the sound equipment is spurred to raise its voice in support. To Zinser’s jam-for-tomorrow sop to the protestors, her benevolent prophesy that a Deaf president will “ONE DAY” be elected, Hlibok and Matlin react with due opprobrium, asking “WHY NOT NOW?/ WHY NOT NOW?”, dismissing her evasive deferral as the answer given “AGAIN AND AGAIN”, and her vague promises of eventual change as “OLD NEWS”.
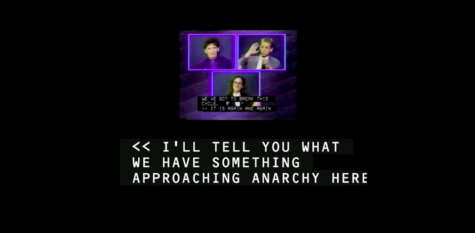
Koppel’s response is to address the TV public with the cosily censorious aside, “I’LL TELL YOU WHAT/ WE HAVE SOMETHING/ APPROACHING ANARCHY HERE”. Deaf political action is simultaneously patronised and indicted as incitement to chaos. For resisting the continuing hegemony of hearing leadership in Deaf space, Deaf activists are reprimanded with quasi-parental scolding: “THE TWO OF YOU ARE/ TALKING AT THE SAME TIME/ WHICH MAKES IT VERY DIFFICULT”. Here, as in the introduction to the programme, the participation of Deaf panellists in the programme is framed as a problem, a hindrance, a complication for hearing viewers. When they don’t capitulate to hearing culture, the Deaf invited guests are repositioned by the host as invaders hitherto, forbearingly “accommodated”; the limits of hospitality are spelt out on the screen.
For Koppel, the “difficulty” of D/deafness is exacerbated by the fact that, as he exclaims, “WE ARE ALSO HEARING/ THE VOICE OF A MAN/ SPEAKING FOR A WOMAN/ AND THE VOICE OF A/ WOMAN FOR A MAN”. Drawing the viewership into queasy complicity, the TV presenter appeals for communicative clemency from Deaf panellists he charges with momentarily inconveniencing the “audience”. Even in this most unusual of open-captioned circumstances, Koppel strives to ensure there is no break in the advantaging of the historically access-advantaged. In his framing of the charge against his guests, the audist conceptualisation of D/deafness as aberrant deficit in a presumed-hearing world intersects once again with the policing of timbre as presumed-stable index of gender identity. By not expressly privileging the hearing audience’s culturally confected expectation of a (phantomic) correlation between vocal timbre and speaker gender, Deaf activists have discomfited those who have been conditioned to countenance no friction.
As Finnegan and Hickman point out—and enact—in Captioning on Captioning, “access work is shaped by relationships”. Or as Alice Wong, Mia Mingus and Sandy Ho have it, “Access is Love”.[35] A D/deaf person’s relationship with a longtime interpreter is a significant, signifying relationship. The “VOICE OF A MAN/ SPEAKING FOR A WOMAN” on Nightline in 1988 is the same one—that of Jack Jason—that can be heard when Matlin appears on TV in 2021. More pressing priorities—of fluent interpretation, mutual regard, professional respect—might reasonably prevail over the recidivist gender binarism policing of a hearing audience not given to having to pay wholehearted attention. Receiver hangs, I think, around its remediation of this moment: the scandal of Koppel’s appeal to the Deaf panellists to “HAVE A LITTLE BIT OF/ COMPASSION FOR THE/ VIEWER WHO’S TRYING TO KEEP UP WITH WHO’S/ SPEAKING”.[36] Texturally, as textually, Brady’s film primes its receivers to appreciate (as though, in all caps, loud and clear) the ideology at play here, so that they might come to recognize it almost everywhere.
A note on the text:
The use of the “D/deaf” signifier is arguably less popular today than at other points in the decades since Woodward proposed it in the 1970s. However it has been preserved here, alongside the explicitly political/cultural “Deaf”, as a way to encompass the plurality of representations and identifications encoded in the historical media artefacts that are processed in Receiver. Like Brady, I approach this material conscious of my situation as a hearing person in a culturally audist world, and am mindful of how these factors shape (and limit) my interpretation; any misunderstandings are all my own. Thanks to Teresa Garratty for all wise and insightful comments, and to Sandra Alland for kind, canny connecting.
Sarah Hayden is currently writing a book about voice in video and thinking about speech, text, technology and access in art. Recent publications include essays on Christopher Kulendran Thomas for Cultural Politics, Emma Wolukau-Wanambwa for LUX, Nancy Holt’s Zeroing In for Holt/Smithson Foundation and liquid voice and sensorial sovereignty for b2o: boundary2 online. She is author of the monograph, Curious Disciplines: Mina Loy and Avant-Garde Artisthood, and co-author with Paul Hegarty, of Peter Roehr–Field Pulsations. In 2020, she curated the Many voices, all of them loved exhibition at John Hansard Gallery, and guest-curated a voiceworks strand for #WIP: work in progress/ working process. Sarah is Associate Professor of Literature and Visual Culture at the University of Southampton and leads the “Voices in the Gallery” research project (AHRC Innovation Fellowship 2019-2023). www.voicesinthegallery.com
[1] Mladen Dolar, A Voice and Nothing More (Cambridge, MA: MIT, 2006), p.32.
[2] Constantina Zavitsanos in Mara Mills and Rebecca Sanchez, “Giving It Away: Constantina Zavitsanos on Disability, Debt, Dependency”, Art Papers 42.04 (Special issue: Disability and the Politics of Visibility) Winter 2018-2019, p.65.
[3] Kristen C. Harmon, “‘If there are Greek epics, there should be Deaf epics’: How Protest Became Poetry”, in Signing the Body Poetic: Essays on American Sign Language Literature, ed. H-Dirksen L. Bauman, Jennifer L. Nelson and Heidi M. Rose, eds. (Berkeley, LA & London: University of California Press), p.169.
[4] Douglas C. Baynton, Forbidden Signs: American Culture and the Campaign Against Sign Language (Chicago & London: University of Chicago Press, 1996), p.4.
[5] H-Dirksen L. Bauman, Jennifer L. Nelson and Heidi M. Rose, “Time Line of ASL Literature Development” in Signing the Body Poetic: Essays on American Sign Language Literature, pp. 241-252.
[6] Baynton, Forbidden Signs: American Culture and the Campaign Against Sign Language, p.4
[7] Jan-Louis Kruger, “Eye tracking in audiovisual translation research”, in The Routledge Handbook of Audiovisual Translation, ed. Luis Pérez-González (London: Routledge 2018), p.357.
[8] Annie Dahne and Roberta Piazza, “‘Subtitles have to become my ears not my eyes’: Pragmatic-stylistic choices behind Closed Captions for the deaf and hard of hearing: the example of Breaking Bad”, in Telecinematic Stylistics, ed. Christian Hoffmann and Monika Kirner-Ludwig (London: Bloomsbury, 2020), pp. 294-295.
[9] Elizabeth Ellcessor, Restricted Access: Media, Disability and the Politics of Participation (New York & London: New York University Press, 2016), p.153.
[10] Sean Zdenek, [reading sounds]: Closed-Captioned Media and Popular Culture (Chicago & London: University of Chicago Press, 2015), p.139, p.107. Google Automatic Captions in YouTube Demo, 2009, https://www.youtube.com/watch?v=kTvHIDKLFqc, qtd. Ellcessor, Restricted Access: Media, Disability and the Politics of Participation, p.2.
[11] “Chrome can now caption audio and video”, https://blog.google/products/chrome/live-caption-chrome/
[12] Nina Sun Eidsheim, Sensing Sound: Singing and Listening as Vibrational Practice (Durham & London: Duke UP, 2015), p.19.
[13] See Zdenek, [reading sounds], p.39 for a table of non-speech information types and pp. 250-252 re what manner of speech identifiers can be entextualized
[14] Lori Emerson, Reading Writing Interfaces: From the Digital to the Bookbound (Minneapolis: University of Minnesota Press, 2014), p.xi, p.1.
[16] Indebted here to Eliza Chandler’s discussion of a point made by Deaf activist Sage Willow in the context of the Cripping the Arts Conference, Toronto in 2019 on Aimi Hamraie’s Contra* Podcast: 2.6: Contra*Curation with Eliza Chandler, Lindsay Fisher, And Sean Lee. See also Jason Palmeri, “Disability Studies, Cultural Analysis, and the Critical Practice of Technical Communication Pedagogy”, Technical Communication Quarterly 15:1 (2006), pp. 49–65.
[17] Janine Butler, “The Visual Experience of Accessing Captioned Television and Digital Videos”, Television & New Media 21: 7 (2020), p. 680.
[19] On studies conducted by TV companies on the perception of open captions among hearing viewers, see Gregory J. Downey, Closed Captioning: Subtitling, Stenography, and the Digital Convergence of Text with Television (Baltimore, Maryland: Johns Hopkins UP, 2008), p.64.
[29] Emily Watlington, “The Radical Accessibility of Video Art (for Hearing People)”, Future Anterior 16:1 (Summer 2019), pp. 111-121. See also Watlington, “Critical Creative Corrective Cacophonous Comical: Closed Captions”, Mousse 68 (Summer 2019).
[30] Emily Watlington, “Letter from the Guest Editor”, Art Papers 42.04, p.3.
[31] Emily Watlington, in “‘Golem Girl’: An Interview with Riva Lehrer”, in Art Papers 42.04, p.48.
[32] Aimi Hamraie, Building Access: Universal Design and the Politics of Disability (Minneapolis & London: University of Minnesota Press, 2017), p.20.
[36] The term “audism” was introduced by the linguist Tom Humphries in 1975 to denote “paternalism and institutional discrimination toward Deaf people”.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookies
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.




-4")
![Liza Sylvestre, Captioned-Channel Surfing (still), 2016. Courtesy: the artist
[Image description: Movie still, close-up of a white man and woman wearing summer clothes in a rural setting looking excited in a phone booth. A caption reads “They are so young and excited and happy.”]](https://lux.org.uk/wp-content/uploads/elementor/thumbs/Sylvestre_16-ptbb2p3a1lcpz2ohcsdguovcjxhrgg26fxoz8fad0w.jpg "Sylvestre_16")

